Quick Sort
| Operation | Method | Time | Adaptive? | In-Place? | Stable? | Online? |
|---|---|---|---|---|---|---|
| Quick sort | Divide et Impera, Partitioning | N | Y | N | N |
Idea
Quick sort belongs to a class of algorithms which use a Divide-et-Impera approach.
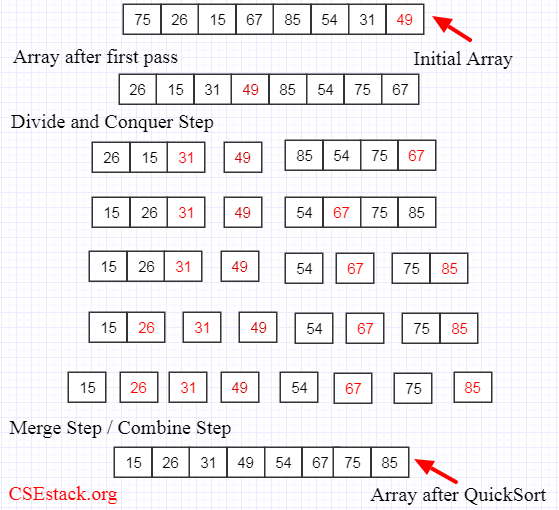
The Algorithm - Divide et Impera
- Divide: After choosing a pivot element from
such that , the vector is partitioned in two sub-vectors and (can be empty), such that is the pivot, the element used to create the partitions and every element that is smaller or larger, is shifted to one of the sub-arrays (so that the conditions are respected).
- Impera: sorts the sub-vectors recursively through quicksort, unless the input is trivially small (
element). - Merge: in this case there is no merge phase, because the algorithm sorts in place
quick_sort(Array A, int p, int r)
if(p < r):
q = Partition(A, p, r);
quick_sort(A, p, q-1);
quick_sort(A, q+1, r);
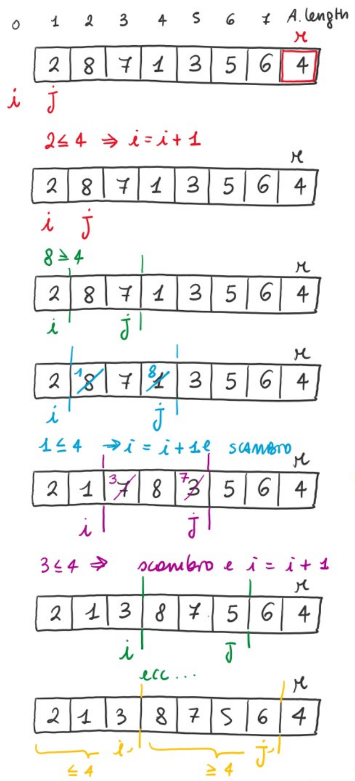
partition(Array A, int p, int r)
x = A[r]; #Last element
i = p-1;
for (j = p to r-1):
if (A[j] <= x): #Swap if the invariant holds true
i++;
swap(A[i], A[j]);
swap(A[i+1], A[r]); #Put pivot back to the right position
return i+1;quick_sort(Array A, int p, int r)
if(p < r):
q = Partition(A, p, r);
quick_sort(A, p, q-1);
quick_sort(A, q+1, r);
partition(Array A, int p, int r)
x = A[r]; #Last element
i = p-1;
for (j = p to r-1):
if (A[j] <= x): #Swap if the invariant holds true
i++;
swap(A[i], A[j]);
swap(A[i+1], A[r]); #Put pivot back to the right position
return i+1;Invariant
We can confirm this is holds true at all times:
- Initialization
- Preservation
- Conclusion:
- At the end of the for block
- This means:
and . - Furthermore, the last two lines of code in the partition function, insert the pivot in the right position by changing it with the leftmost element larger than x.
- At the end of the for block
Time Complexity
And
Where
is the count of elements of the first sub-array is the count of elements of the second sub-array (excluding the pivot )
Demonstration - Worst Case
In the worst case the sub-arrays are highly unbalanced
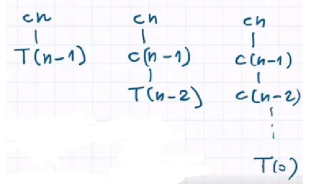
Demonstration - Best Case
In the best case the sub-arrays contain exactly almost half of the total elements respectively
By the Master Theorem
Demonstration - Average Case (constant)
In the average case, we find a constant repartition of the subarrays for example
By the Occurrences Tree method we find that:
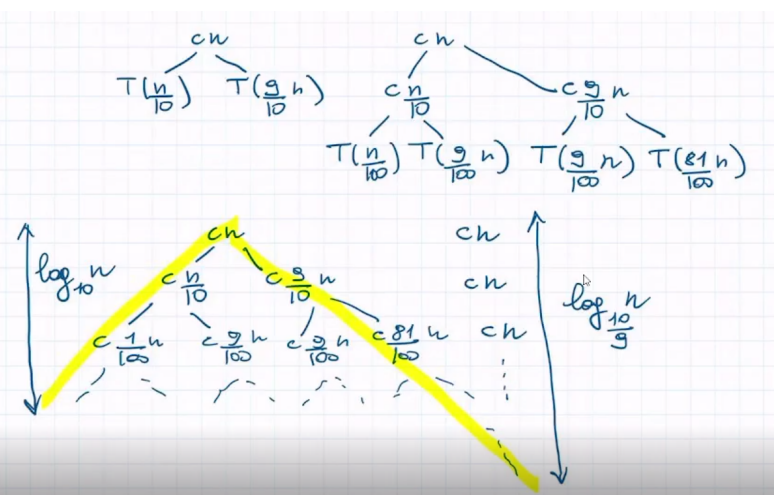
So:
- The height of the tree is
- The longest path from the root, to a leaf here is found by keep going right,
- Which is where the recursion stops
- The maximum cost of a level is
- Every level has cost
until we reach the depth where it becomes the upperbound for the cost of a level
- Every level has cost
Then:
From this we can generalize that:
Demonstration - Average Case (non-constant)
In the average case where there are two options that keep repeating:
- We assume that the input's permutations are i.i.d
Then:
Avoiding Worst Case: Randomized Version
Instead of choosing
- We assume all the keys are distinct
#returns random integer between p and r
int randomized_partition(int arr[], int p, int r)
int i = random(p,r);
swap(&arr, i, r); #swap arr[i] and arr[j]
return partition(arr, p, r);
randomized_quicksort(int arr[], int p, int r)
if(p < r):
q = randomized_partition(arr, p, r);
randomized_quicksort(arr, p, q - 1);
randomized_quicksort(arr, q + 1, r);#returns random integer between p and r
int randomized_partition(int arr[], int p, int r)
int i = random(p,r);
swap(&arr, i, r); #swap arr[i] and arr[j]
return partition(arr, p, r);
randomized_quicksort(int arr[], int p, int r)
if(p < r):
q = randomized_partition(arr, p, r);
randomized_quicksort(arr, p, q - 1);
randomized_quicksort(arr, q + 1, r);Pros:
does not depend on the input's order - No assumption on the input's distribution.
- No specific input can define the worst case
- The random number generator defines the worst case
- It is 3 to 4 times faster than the normal version.
Optimization - Insertionsort on small vectors
By using a value m 5 <= m <= 25 to have a range of cases where the insertion sort overrides the main algorithm can help to improve the average case scenario.
Case 1: We can either sort it only if the input is in range
quicksort(int * arr, int p, int r)
if(r - p <= M):
insertionsort(arr);quicksort(int * arr, int p, int r)
if(r - p <= M):
insertionsort(arr);Case 2:
quicksort(int * arr, int p, int r)
if(r - p <= M):
return;
sort(int * arr, int p, int r)
quicksort(arr, p, r); # partially sorted vectors
insertionsort(arr); # we sort the rest with insertion sortquicksort(int * arr, int p, int r)
if(r - p <= M):
return;
sort(int * arr, int p, int r)
quicksort(arr, p, r); # partially sorted vectors
insertionsort(arr); # we sort the rest with insertion sortOptimization 2 - Median as pivot
Using a value
- Choosing the median out of three elements inside an unsorted vector:
- A leftmost element
- A rightmost element
- A center element
- Swapping it with
- Applying the algorithm
Optimization 3 - Dutch Flag (Tri-Partition)
When we find duplicates, not even randomizing the choice of the pivot can help much.
Instead, of dividing the vector in 2 parts we divide it in 3 parts:
- Partition with elements
- Partition with elements
- Partition with elements
This slightly changes the invariant, but the main idea stays the same.
Partition:
- Permutation of the elements in
- Returns
and ,
partition(int * arr, int p, int r)
int x = arr[r];
int min = p, eq = p, max = r;
# Theta(r-p)
while(eq < max):
if(arr[eq] < x):
swap(arr, min, eq);
eq++;
min++;
else if(arr[eq] == x):
eq++;
else:
max--;
swap(arr, max, eq);
swap(arr, r, max);
return [min, max]; #pair
quicksort(int * arr, int p, int r)
if(p < r):
int[] qt = partition(arr, p, r);
quicksort(arr, p, q - 1);
quicksort(arr, t + 1, r);partition(int * arr, int p, int r)
int x = arr[r];
int min = p, eq = p, max = r;
# Theta(r-p)
while(eq < max):
if(arr[eq] < x):
swap(arr, min, eq);
eq++;
min++;
else if(arr[eq] == x):
eq++;
else:
max--;
swap(arr, max, eq);
swap(arr, r, max);
return [min, max]; #pair
quicksort(int * arr, int p, int r)
if(p < r):
int[] qt = partition(arr, p, r);
quicksort(arr, p, q - 1);
quicksort(arr, t + 1, r);Invariant
We obtain something like this:
| < x | = x | ? | > x | x |
|p |min | eq| max | r |
We can confirm this is holds true at all times:
- Initialization
- Preservation
- Conclusion: When the execution ends, we have
- The last two lines swap the pivot
with the first element larger than - We obtain the desired partition
- The last two lines swap the pivot
The result is:
| < x | = x | > x | x |
|p |min | max | r |
Complexity
If all the elements are equal
Conclusion
Pro:
- In-Loco
- Worst Case is very rare, and normally it is very efficient
- Randomizing the pivot is a solution for when input is sorted
- Tri-partition improves the computing complexity
Con:
- Worst Case T(n) = O(n**2)
- Not Stable
- Not adaptive: slow when input is already sorted (asc/desc) or all the elements have equal values